File Info
| Exam | Developing SQL Databases |
| Number | 70-762 |
| File Name | Microsoft.70-762.ActualTests.2018-09-26.83q.vcex |
| Size | 4 MB |
| Posted | Sep 26, 2018 |
| Download | Microsoft.70-762.ActualTests.2018-09-26.83q.vcex |
How to open VCEX & EXAM Files?
Files with VCEX & EXAM extensions can be opened by ProfExam Simulator.
Coupon: MASTEREXAM
With discount: 20%





Demo Questions
Question 1
You have a database that is experiencing deadlock issues when users run queries.
You need to ensure that all deadlocks are recorded in XML format.
What should you do?
- Create a Microsoft SQL Server Integration Services package that uses sys.dm_tran_locks.
- Enable trace flag 1224 by using the Database Cpmsistency Checker(BDCC).
- Enable trace flag 1222 in the startup options for Microsoft SQL Server.
- Use the Microsoft SQL Server Profiler Lock:Deadlock event class.
Correct answer: C
Explanation:
When deadlocks occur, trace flag 1204 and trace flag 1222 return information that is capturedin the SQL Server error log. Trace flag 1204 reports deadlock information formatted by each node involved in the deadlock. Trace flag 1222 formats deadlock information, first by processes and then by resources. The output format for Trace Flag 1222 only returns information in an XML-like format. References:https://technet.microsoft.com/en-us/library/ms178104(v=sql.105).aspx When deadlocks occur, trace flag 1204 and trace flag 1222 return information that is capturedin the SQL Server error log. Trace flag 1204 reports deadlock information formatted by each node involved in the deadlock. Trace flag 1222 formats deadlock information, first by processes and then by resources.
The output format for Trace Flag 1222 only returns information in an XML-like format.
References:https://technet.microsoft.com/en-us/library/ms178104(v=sql.105).aspx
Question 2
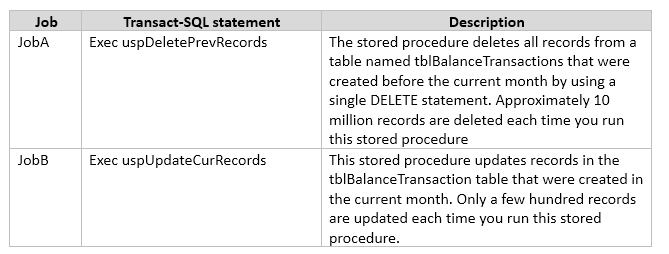
You are developing an application that connects to a database.
The application runs the following jobs:
The READ_COMMITTED_SNAPSHOT database option is set to OFF, and auto-content is set to ON. Within the stored procedures, no explicit transactions are defined.
If JobB starts before JobA, it can finish in seconds. If JobA starts first, JobB takes a long time to complete.
You need to use Microsoft SQL Server Profiler to determine whether the blocking that you observe in JobB is caused by locks acquired by JobA.
Which trace event class in the Locks event category should you use?
- LockAcquired
- LockCancel
- LockDeadlock
- LockEscalation
Correct answer: A
Explanation:
The Lock:Acquiredevent class indicates that acquisition of a lock on a resource, such asa data page, has been achieved.The Lock:Acquired and Lock:Released event classes can be used to monitor when objects are being locked, the type of locks taken, and for how long the locks were retained. Locks retained for long periods of time may cause contention issues and should be investigated. The Lock:Acquiredevent class indicates that acquisition of a lock on a resource, such asa data page, has been achieved.
The Lock:Acquired and Lock:Released event classes can be used to monitor when objects are being locked, the type of locks taken, and for how long the locks were retained. Locks retained for long periods of time may cause contention issues and should be investigated.
Question 3
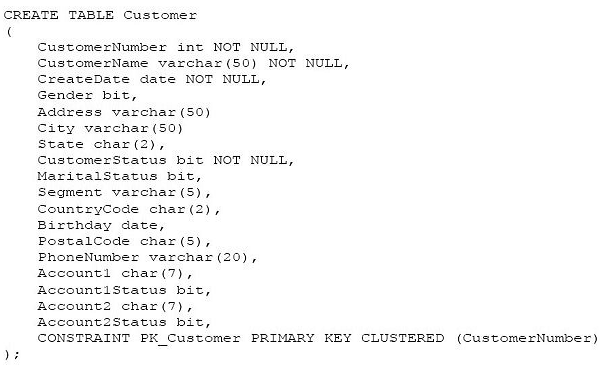


Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named DB1 that contains the following tables: Customer, CustomerToAccountBridge, and CustomerDetails. The three tables are part of the Sales schema. The database also contains a schema named Website. You create the Customer table by running the following Transact-SQL statement:
The value of the CustomerStatus column is equal to one for active customers. The value of the Account1Status and Account2Status columns are equal to one for active accounts. The following table displays selected columns and rows from the Customer table.
You plan to create a view named Website.Customer and a view named Sales.FemaleCustomers.
Website.Customer must meet the following requirements:
- Allow users access to the CustomerName and CustomerNumber columns for active customers.
- Allow changes to the columns that the view references. Modified data must be visible through the view.
- Prevent the view from being published as part of Microsoft SQL Server replication.
Sales.Female.Customers must meet the following requirements:
- Allow users access to the CustomerName, Address, City, State and PostalCode columns.
- Prevent changes to the columns that the view references.
- Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary. The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You must update the design of the Customer table to meet the following requirements.
- You must be able to store up to 50 accounts for each customer.
- Users must be able to retrieve customer information by supplying an account number.
- Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
Correct answer: D
Explanation:
Two tables is enough.CustomerID must be in both tables. Two tables is enough.CustomerID must be in both tables.
Question 4
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named DB1 that contains the following tables: Customer, CustomerToAccountBridge, and CustomerDetails. The three tables are part of the Sales schema. The database also contains a schema named Website. You create the Customer table by running the following Transact-SQL statement:
The value of the CustomerStatus column is equal to one for active customers. The value of the Account1Status and Account2Status columns are equal to one for active accounts. The following table displays selected columns and rows from the Customer table.
You plan to create a view named Website.Customer and a view named Sales.FemaleCustomers.
Website.Customer must meet the following requirements:
- Allow users access to the CustomerName and CustomerNumber columns for active customers.
- Allow changes to the columns that the view references. Modified data must be visible through the view.
- Prevent the view from being published as part of Microsoft SQL Server replication.
Sales.Female.Customers must meet the following requirements:
- Allow users access to the CustomerName, Address, City, State and PostalCode columns.
- Prevent changes to the columns that the view references.
- Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary. The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the uspUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When you start uspUpdateCustomerSummary, there are no active transactions. The procedure fails at the second update statement due to a CHECK constraint violation on the TotalDepositAccountCount column.
What is the impact of the stored procedure on the CustomerDetails table?
- The value of the TotalAccountCount column decreased.
- The value of the TotalDepositAccountCount column is decreased.
- The statement that modifies TotalDepositAccountCount is excluded from the transaction.
- The value of the TotalAccountCount column is not changed.
Correct answer: D
Question 5
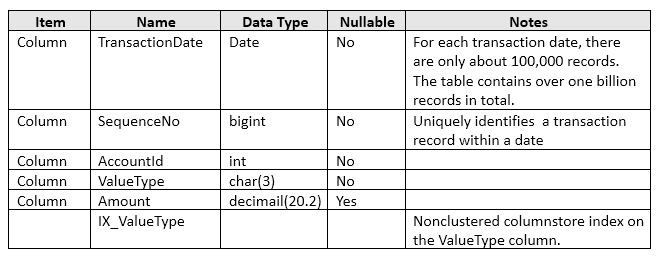

Note: This question is part of a series of questions that use the same answer choices. An answer choice may be correct for more than one question on the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the following table:
Users report that the following query takes a long time to complete.
You need to create an index that:
- improves the query performance
- does not impact the existing index
- minimizes storage size of the table (inclusive of index pages).
What should you do?
- Create aclustered index on the table.
- Create a nonclustered index on the table.
- Create a nonclustered filtered index on the table.
- Create a clustered columnstore index on the table.
- Create a nonclustered columnstore index on the table.
- Create a hashindex on the table.
Correct answer: C
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes. A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
Question 6

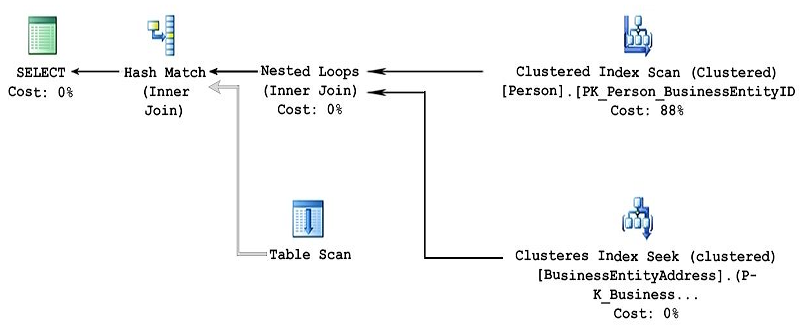
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question os independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a database named DB1. There is no memory-optimized filegroup in the database.
You run the following query:
The following image displays the execution plan the query optimizer generates for this query:
Users frequently run the same query with different values for the local variable @lastName. The table named Person is persisted on disk.
You need to create an index on the Person.Person table that meets the following requirements:
- All users must be able to benefit from the index.
- FirstName must be added to the index as an included column.
What should you do?
- Create a clustered index on the table.
- Create a nonclustered index on the table.
- Create a nonclustered filtered index on the table.
- Create a clustered columnstore index on the table.
- Create a nonclustered columnstore index on the table.
- Create a hash index on the table.
Correct answer: B
Explanation:
By including nonkey columns, you can create nonclustered indexes that cover more queries. This is because the nonkeycolumns have the following benefits:They can be data types not allowed as index key columns. They are not considered by the Database Engine when calculating the number of index key columns or index key size. By including nonkey columns, you can create nonclustered indexes that cover more queries. This is because the nonkeycolumns have the following benefits:
They can be data types not allowed as index key columns.
They are not considered by the Database Engine when calculating the number of index key columns or index key size.
Question 7
Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series. Information and details provided in a question apply only to that question.
You have a reporting database that includes a non-partitioned fact table named Fact_Sales. The table is persisted on disk.
Users report that their queries take a long time to complete. The system administrator reports that the table takes too much space in the database. You observe that there are no indexes defined on the table, and many columns have repeating values.
You need to create the most efficient index on the table, minimize disk storage and improve reporting query performance.
What should you do?
- Create a clustered index on the table.
- Create a nonclustered index on the table.
- Create a nonclustered filtered index on the table.
- Create a clustered columnstore index on the table.
- Create a nonclustered columnstore index on the table.
- Create a hash index on the table.
Correct answer: D
Explanation:
The columnstore index is the standard for storing and querying largedata warehousing fact tables. It uses column-based data storage and query processing to achieve up to 10x query performance gains in your data warehouse over traditional row-oriented storage, and up to 10x data compression over the uncompressed data size. A clustered columnstore index is the physical storage for the entire table. The columnstore index is the standard for storing and querying largedata warehousing fact tables. It uses column-based data storage and query processing to achieve up to 10x query performance gains in your data warehouse over traditional row-oriented storage, and up to 10x data compression over the uncompressed data size.
A clustered columnstore index is the physical storage for the entire table.
Question 8

Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series. Information and details provided in a question apply only to that question.
You have a database named DB1. The database does not use a memory-optimized filegroup. The database contains a table named Table1. The table must support the following workloads:
You need to add the most efficient index to support the new OLTP workload, while not deteriorating the existing Reporting query performance.
What should you do?
- Create a clustered index on the table.
- Create a nonclustered index on the table.
- Create a nonclustered filtered index on the table.
- Create a clustered columnstore index on the table.
- Create a nonclustered columnstore index on the table.
- Create a hash index on the table.
Correct answer: C
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes. References:https://technet.microsoft.com/en-us/library/cc280372(v=sql.105).aspx A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
References:https://technet.microsoft.com/en-us/library/cc280372(v=sql.105).aspx
Question 9

Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series. Information and details provided in a question apply only to that question.
You have a database named DB1. The database does not have a memory optimized filegroup.
You create a table by running the following Transact-SQL statement:
The table is currently used for OLTP workloads. The analytics user group needs to perform real-time operational analytics that scan most of the records in the table to aggregate on a number of columns.
You need to add the most efficient index to support the analytics workload without changing the OLTP application.
What should you do?
- Create a clustered indexon the table.
- Create a nonclustered index on the table.
- Create a nonclustered filtered index on the table.
- Create a clustered columnstore index on the table.
- Create a nonclustered columnstore index on the table.
- Create a hash index on the table.
Correct answer: E
Explanation:
A nonclustered columnstore index enables real-time operational analytics in which the OLTP workload uses the underlying clustered index, while analytics run concurrently on the columnstore index. Columnstore indexes can achieve up to 100xbetter performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes. These recommendations will help your queries achieve the very fast query performance that columnstore indexes are designed to provide. References:https://msdn.microsoft.com/en-us/library/gg492088.aspx A nonclustered columnstore index enables real-time operational analytics in which the OLTP workload uses the underlying clustered index, while analytics run concurrently on the columnstore index.
Columnstore indexes can achieve up to 100xbetter performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes. These recommendations will help your queries achieve the very fast query performance that columnstore indexes are designed to provide.
References:https://msdn.microsoft.com/en-us/library/gg492088.aspx
Question 10
You use Microsoft SQL Server Profile to evaluate a query named Query1. The Profiler report indicates the following issues:
- At each level of the query plan, a low total number of rows are processed.
- The query uses many operations. This results in a high overall cost for the query.
You need to identify the information that will be useful for the optimizer.
What should you do?
- Start a SQL Server Profiler trace for the event class Auto Stats in the Performance event category.
- Create one Extended Events session with the sqlserver.missing_column_statistics event added.
- Start a SQL Server Profiler trace for the event class Soft Warnings in the Errors and Warnings event category.
- Create one Extended Events session with the sqlserver.missing_join_predicate event added.
Correct answer: D
Explanation:
The Missing Join Predicate event class indicates that a query is being executed that has no join predicate. This could result in a long-running query. The Missing Join Predicate event class indicates that a query is being executed that has no join predicate. This could result in a long-running query.

